Entre la persona y la máscara:
el
uso del autotune
en la canción "Goteo"
Desde comienzos del siglo XX
hemos sido testigos del vertiginoso avance de las tecnologías de grabación,
procesamiento y reproducción del sonido. Asimismo, las prácticas de producción
fonográfica se han modificado, alejándose de la concepción documental de los
medios analógicos de grabación y reproducción, cuyo impacto en el sonido
grabado pretendió invisibilizarse detrás de retóricas de la transparencia. Esto
se debe, principalmente, a la incidencia que tienen sobre el sonido las
operaciones realizadas por los ingenieros y técnicos de sonido, tanto durante
su grabación como en su postproducción.
Por otra parte, el advenimiento
de las tecnologías digitales dedicadas a la producción fonográfica,
paralelamente a la creación hacia fines del siglo XX de la world wide web y el intercambio de información
que ella habilitó, propiciaron no sólo una dispersión sin precedentes de
tecnología específica para la creación musical, sino también la proliferación
de usos creativos inicialmente no previstos en su diseño. De hecho, muchos de
ellos cristalizaron rápidamente prácticas que originaron efectos fonográficos
singulares, erigidos también como rasgos característicos de diversos estilos
musicales.
No
obstante, ocurre que la acumulación de prácticas, tanto estandarizadas como
creativas, pueden colisionar eventualmente con los supuestos en torno a la
autenticidad de un registro fonográfico, y en cuanto al límite en el cual una
práctica fonográfica específica puede constituirse como un engaño. En este
sentido, el objetivo del presente trabajo es observar y describir los
diferentes modos de uso de la tecnología de corrección de afinación conocida
popularmente como autotune
en el fonograma en vivo de la canción "Goteo", perteneciente a Duki, cantante argentino de trap.
Guían nuestro trabajo las siguientes hipótesis: en primer lugar, afirmar que la
implementación del autotune
es indispensable para el diseño sonoro de la persona musical y su vocalidad resultante. Segundo, sostener que su
implementación responde tanto a una decisión correctiva como
artístico-creativa.
Palabras clave: autotune, persona, vocalidad,
trap, Duki
Between the mask and the persona: uses of the autotune in "Goteo"
Since the beginning of the 20th
century we have witnessed the vertiginous advance of sound recording,
processing and reproduction technologies. Likewise, phonographic production
practices have been modified, moving away from the documentary conception of
analog recording and reproduction media, whose impact on recorded sound sought
to make itself invisible behind rhetoric of transparency. This is mainly due to
the impact that the operations carried out by sound engineers and technicians
have on sound, both during recording and post-production.
On the other hand, the advent of
digital technologies dedicated to phonographic production, parallel to the
creation towards the end of the 20th century of the world wide web and the
exchange of information it enabled, led not only to an unprecedented dispersion
of specific technology for musical creation, but also to the proliferation of
creative uses not initially foreseen in its design. In fact, many of them
quickly crystallized into practices that gave rise to unique phonographic
effects, also erected as characteristic features of various musical styles.
However, it happens that the
accumulation of practices, both standardized and creative, may eventually
collide with assumptions about the authenticity of a phonographic record, and
about the limit at which a specific phonographic practice can constitute a
hoax. In this sense, the objective of this paper is to observe and describe the
different modes of use of the pitch correction technology popularly known as
autotune in the live version of the song "Goteo",
belonging to Duki, an argentine
trap artist. The following hypotheses guide our work: first, to affirm that the
implementation of autotune is essential for the sound design of the musical
person. Second, to maintain that its implementation responds to both a
corrective and an artistic-creative decision.
Keywords: autotune, persona, vocality, trap, Duki
1. Introducción[1]
Música y tecnología están íntimamente
relacionadas. Según Luciano Lahiteau, ellas “ … son
indisociables, y no es posible entender el desarrollo de la primera sin atender
la evolución de la segunda”.[2] En
la misma línea, Joseph Auner refuerza explicando que
en ningún
otro aspecto de nuestras vidas se ha producido una penetración en lo humano tan
completa por parte de la máquina como en la música. Cada etapa de producción,
distribución y consumo en la vida musical del mundo industrializado ha sido tan
permeada por la tecnología que ya ni siquiera reconocemos dispositivos complejos
como el piano en tanto artefactos tecnológicos.[3]
En este sentido, la fonografía y sus
prácticas específicas de producción y reproducción del sonido pueden
considerarse como el epítome de lo afirmado por Lahiteau
y Auner. Desde la grabación hasta la postproducción y
publicación de un fonograma, todas las instancias de la producción fonográfica
se encuentran inervadas por tecnologías específicas que, en su mayoría, no
actúan únicamente como continentes asépticos de la música, sino todo lo
contrario: se erigen como su misma condición de existencia. Existencia
portadora de una diferencia ontológica radical respecto de lo que la originó.
En este sentido, nuevamente con Lahiteau, “… la
música grabada es en esencia un artificio, puesto que fija en un soporte físico
o digital algo tan volátil e insustancial como una serie de sonidos organizados
en el tiempo”.[4] No
obstante, y para evitar caer en un determinismo técnico-tecnológico, se impone
recuperar las voces de Simon Frith y Simon Zagorski-Thomas, quienes
afirman que “en el estudio [de grabación] las decisiones técnicas son
estéticas, las decisiones estéticas son técnicas y todas las decisiones son
musicales”.[5]
Desde los años sesenta en adelante, el phonographic staging[6]
o, como lo llamaremos aquí, las presentaciones fonográficas[7]
de las músicas populares han tendido progresivamente hacia una concepción de la
producción fonográfica que aspira más a crear una realidad de la ilusión que
una ilusión de realidad.[8] Por
ejemplo, desde el nacimiento de la figura del crooner en la música popular a mediados del siglo XX, cuyo auge
está ligado íntimamente a la invención del micrófono eléctrico,[9]
hasta los procesamientos y manipulaciones en obras electroacústicas de
compositores de música de tradición escrita tales como Karlheinz
Stockhausen o Luciano Berio,[10] la
voz grabada ha sido objeto de múltiples operaciones de procesamiento y
transformación, combinando finalidades tanto artístico-creativas como
correctivas. Si, como afirma Philip Tagg, “la voz es
el instrumento musical primario de la humanidad”,[11]
es necesario entonces comprender de qué manera se la manipula en la producción
fonográfica, cuáles son las decisiones que se toman y las operaciones que se le
realizan. En sí misma, la voz es portadora de una diferencia notable respecto a
otros instrumentos o sonidos que pueden grabarse. Como sostiene Lacasse,
Más que ser
un mero vehículo de la letra, la voz actúa a través de la exposición parcial
del cuerpo del cantante, como el índice aural de la persona del artista y de
las emociones que representa. Las características de la canción, entonces,
viven a través de las voces del cantante, que son presentadas fonográficamente
con la ayuda de técnicas de grabación.[12]
En este sentido, Greg Milner
nos recuerda que, actualmente,
si estás
escuchando una canción en una radio que reproduce rock, pop o R&B nuevo o
más o menos reciente, lo más probable es que haya una gran posibilidad de que
las voces hayan sido procesadas durante la grabación o la mezcla con Auto-Tune,
un software que corrige automáticamente la afinación de un cantante, que puede
crear un efecto inhumano. Todo este tiempo estuviste escuchando voces
distintivamente inhumanas, pensándolas como humanas.[13]
En este trabajo proponemos analizar el uso
del procesador autotune[14]
de la canción "Goteo" perteneciente a Duki,
cantante argentino de trap,[15]
en el fonograma registrado para el ciclo Paredón
session[16]
(en adelante, el fonograma en vivo).[17]
El centro de interés radicará en indagar tanto en las motivaciones que llevaron
al uso de este procesador, como en la modalidad en la que ha sido empleado para
modelar la persona musical y la vocalidad resultante.
Para ello, comenzaremos por exponer una breve historia del autotune, tomando en
consideración no solamente sus aspectos técnicos, sino también los usos
creativos que se han hecho de él y las controversias que, desde su lanzamiento
a fines del siglo XX hasta la fecha, continúan gravitando a su alrededor.
Luego, realizaremos una contextualización sucinta del trap
desde sus orígenes en los Estados Unidos hasta la actualidad del estilo en la
Argentina. Esto nos llevará directamente a la figura de Duki,
de quien haremos una minima biographica
sobre su carrera y las características salientes de su música. El análisis del
objeto de estudio dinamizará al fonograma elegido con el marco teórico
propuesto. En este sentido, comenzaremos por describir aspectos del fonograma
que consideramos pertinentes, para luego avanzar hacia el análisis de la
"persona musical",[18] su
diseño, cómo tensiona ésta con el concepto de máscara y de qué manera el autotune se erige
como un rasgo saliente de la vocalidad resultante. El
análisis será complementado por los aportes que Mariano Bilinkis[19]
(ingeniero de sonido que mezcló y masterizó el fonograma en vivo) y Ramiro
Molina[20]
(guitarrista que tocó en el fonograma en vivo) han realizado en el marco de
entrevistas otorgadas al autor de este trabajo. Para finalizar, acompañaremos
las conclusiones generales referidas a "Goteo" con reflexiones de
naturaleza más amplia sobre las problemáticas de autenticidad y engaño que
suelen gravitar en torno a la producción fonográfica en el trap.
El Auto-Tune es un software de audio concebido originalmente como una herramienta de corrección
de afinación. Diseñado por Harold Andrew “Andy” Hildebrand (Coronado, Estados
Unidos), ingeniero geofísico de profesión y flautista aficionado, quien enfocó
su trabajo en el desarrollo de métodos digitales de procesamiento de señal que
pudiesen ser utilizados para identificar la presencia de depósitos de petróleo
a partir del análisis de reflexiones sonoras de las capas subterráneas de la
tierra producidas por la explosión de dinamita. En 1989, Hildebrand decidió
alejarse de la ingeniería geofísica para dedicarse a la música, comenzando sus
estudios formales en la Escuela de Música de Shephard
(Universidad de Rice, Texas, Estados Unidos). Allí nació su intuición en
relación a la posibilidad de tomar como punto de partida el modelo
originalmente elaborado con propósitos geofísicos para crear un software capaz
de detectar, evaluar y modificar, todo en tiempo real, la afinación de una
melodía cantada. En el año 1996, luego
de desarrollar y publicar exitosamente diversos softwares de procesamiento de
sonido con base en la tecnología DSP,[21] Hildebrand creó a partir del modelo
matemático[22]
utilizado en sus investigaciones previas la primera versión estable del
software Auto-Tune, que sería el primero capaz de modificar en tiempo real y de
manera semi automática[23] la
afinación de una voz grabada. O, recuperando la expresión de Jaime Altozano,
ampliamente aceptada tanto por especialistas y no especialistas en la materia,
el responsable de “crear la caja mágica que hacía que todo el mundo pudiera
cantar”.[24] Un
año después, en 1997, Hildebrand fundó la empresa Antares, que será la
encargada de comercializar el software Antares Auto-Tune y sus derivados desde
entonces hasta la actualidad. La primera versión del software fue concebida
como plug-in,[25]
para ser usado en una DAW.[26] En
la imagen expuesta a continuación mostramos la interfaz gráfica de la primera
versión software del Antares
Auto-Tune (Imagen 1):
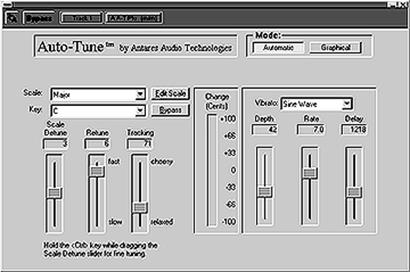 Imagen 1:
interfaz gráfica del software Antares Auto-Tune
en su versión plug-in de 1997.
Imagen 1:
interfaz gráfica del software Antares Auto-Tune
en su versión plug-in de 1997.
Fuente: http://www.dancetech.com/item.cfm?threadid=357&lang=0
Es importante señalar que, desde la intención
original de Hildebrand, el Auto-Tune se diferencia de otros procesamientos
analógicos de la voz, tales como el Vocoder o la TalkBox, que, si bien pueden producir una resultante sonora
similar, difieren tanto respecto de su intención original como del entorno en
el que funcionan. Mientras que tanto el Vocoder[27]
como la TalkBox fueron empleados en la producción
fonográfica como un efecto, la finalidad original del Auto-Tune fue la de
corregir interpretaciones vocales cuya afinación fuese considerada como
imprecisa o incorrecta.
Resulta pertinente recordar que antes de la
creación y comercialización del Antares Auto-Tune a finales de los años ‘90,
existieron prácticas de producción fonográfica mediante las que se buscaba
modificar la afinación de una melodía vocal grabada. En efecto, la siguiente
cita recupera la palabra del ingeniero de audio argentino Gustavo Borner, en la que describe las dificultades que tales
prácticas implicaban para su concreción:
Al final de
los ‘80 y principios de los ‘90 afinábamos con lo que había a mano. La AMS DMX
15-80S y el Eventide H3000 tenían cambio de tono
(pitch shifter), así que pasabas la grabación de un
canal a otro en una máquina de 24, 42 o 48 canales e ibas pinchando en cada
canal nuevo, pasando por uno de estos aparatos con los céntimos de afinación
correctos. ¡Tardabas años![28]
En resumen, la novedad que introdujo el
Antares Auto-Tune fue triple: en primer lugar, a diferencia del Vocoder o de la TalkBox, continuó
el cambio iniciado por el procesador Eventide H3000.
Es decir, en primer lugar, el Auto-Tune es un procesador programado para
funcionar en un entorno digital; segundo, es capaz de realizar la modificación
de altura en tiempo real, y a velocidades que pueden acercarse a lo
audiblemente instantáneo. Finalmente, en tercer lugar, la modificación de
altura la realiza el software de manera semi automática.
La incorporación del Auto-Tune a las
producciones musicales implicó un enorme avance para la industria musical,
principalmente en términos de ahorro de tiempo y eficiencia en instancias de
postproducción. Por su capacidad de procesamiento en tiempo real y fácil
operación, redujo drásticamente los tiempos que, previo a su utilización, eran
necesarios para regrabar interpretaciones y/o editar manualmente
interpretaciones vocales con afinaciones defectuosas. En palabras de
Hildebrand, “el impacto real de Auto-Tune es que cambió la forma en la que los
estudios producen las voces”.[29]
2.2. Entre creación y controversia
En el mes de octubre de 1998, la cantante
Cher publicó su canción "Believe",[30]
producida por Mark Taylor y Brian Rawling. En ella se
podía apreciar una transformación en el sonido de la voz que asalta a la
audición. Entrevistados en su momento,[31]
ambos productores no admitieron públicamente que se trataba de un uso heterodoxo del Auto-Tune, mientras que Cher
reconoció[32]
el uso extremo de un efecto empleado como factor de diferenciación de esta
canción respecto de la música mainstream
del momento, sin entrar en detalles. Según Eckard, de
esta canción “lo más memorable no fue que las vocales no sonaban mecánicas o
sintetizadas (eso ya se había hecho antes), sino la forma en que se movían,
brincando de pitch en pitch”.[33]
Lahiteau amplía:
Era algo que saltaba al oído y que podía confundirse con una falla,
una imperfección grosera. Hacía que la voz sonara artificial e inhumana, como
si Cher cantara desde un cadalso de bytes. Y era precisamente eso lo que la
hacía atractiva y pregnante. Algo no estaba bien y
era imposible que la atención del oyente no fuera seducida por esa extrañeza.[34]
Concretamente, la producción de este melisma
digital[35] se
debe a un uso específico de uno de los parámetros del autotune: el Retune speed.[36]
Su función permite al usuario configurar cuántos milisegundos le tomará al
software corregir la afinación de las notas de la melodía procesada. Si éste es configurado a cero milisegundos, la
modificación de la altura será audiblemente instantánea,[37]
alterando drásticamente la afinación original de la melodía. Además del centro
de afinación de cada nota, el pasaje entre cada una de ellas también se verá
comprometido por el quasi
nulo tiempo disponible para cambiar "humanamente" de una nota a otra.
Esto resulta en la sonoridad inhumana y "robótica" con la que se
acostumbra describir este modo de empleo del autotune, en la que se suele
apreciar una discretización de las notas que conforman una melodía vocal
grabada. Esta configuración se conoció y popularizó en el ámbito de la
producción fonográfica como zero setting o hard tuning,[38]
mientras que la recepción no especializada de esta resultante sonora lo llamó
en un primer momento “Cher effect" o efecto Cher. A este le siguió, en el año
2005, el “T-Pain
effect” o “efecto T-Pain”,
producto del uso explícito y permanente que el rapero estadounidense Faheem Resheed Najm (1984, Estados Unidos), conocido popularmente como T-Pain, hizo del Auto-Tune
en su álbum Rappa Turnt Sanga (Konvict, Jive, Zomba) lanzado ese año. De acuerdo con la periodista
especializada Lobad Noor, “Fue el uso pivotante que
T-Pain hizo de la tecnología como una herramienta
estilística, más que como una ayuda para mejorar vocales defectuosas, lo que
empujó al efecto vocal más aún dentro del mainstream
y propulsó otros experimentos con él también”.[39]
Cabe destacar que la cantidad de autotune,
identificable a través de la interfaz gráfica del plugin, y la extensión de su
empleo (cuántas veces es utilizado a lo largo de toda la duración del fonograma)
no es lo único que diferencia el uso de este procesamiento entre T-Pain y Cher. La diferencia, fundamental para nuestro
trabajo, se encuentra en el momento de la performance en el que el software fue
utilizado. En este sentido, resulta pertinente recuperar las
conceptualizaciones de input device y output device[40] que
permiten pensar el uso de los procesadores digitales en las diferentes
instancias de una performance grabada. Mientras que "Believe"
contiene fragmentos de la letra estratégicamente procesados con la
configuración hard tuning, el
procesamiento es realizado a posteriori de la grabación, en la instancia de
postproducción del fonograma. Es decir, el Auto-Tune
fue utilizado como output device. Por el contrario, T-Pain
utiliza el Auto-Tune en su configuración
hard tuning
durante la performance vocal. Es decir que el registro fonográfico que se hace
de la performance del cantante ya incluye al Auto-Tune en esta configuración usado como input device.
Más allá de todo lo
descripto hasta aquí, encontramos que el uso creativo del autotune no evitó la rápida
emergencia de múltiples controversias que, según entendemos, parten
fundamentalmente de dos conceptos íntimamente vinculados entre sí: autenticidad
y engaño. En cuanto a la primera, se impone recordar que, más allá de los usos
del autotune
y de los procesamientos de sonido que pueden ser calificados como artificiosos,
las tecnologías de transmisión, registro, procesamiento y reproducción del
sonido se han valido históricamente de conocimientos sobre el aparato auditivo
humano (particularmente los estudios vinculados con la Psicoacústica)
para desarrollar artefactos tecnológicos eficaces para sus fines. En este
sentido y a modo de ejemplo, podemos mencionar que los estudios realizados para
el desarrollo de la telefonía o del formato MP3 incluyen decisiones que
"engañan" al aparato auditivo, explotando diferentes aspectos de
éste.[41]
Por otro lado, es conocido ya el argumento de
que cualquier operación realizada a posteriori sobre el sonido
registrado implica algún grado de pérdida de autenticidad de éste. Recordemos,
por ejemplo, la crítica acérrima que realizara Eric Clapton en relación con la
música grabada, ponderando la música en vivo[42]
o la iniciativa Live means
live, lanzada en el año 2013 en la misma línea.[43]
Concomitantemente, entendemos que las controversias en torno al engaño[44] que
implica para muchos el uso del autotune comparten el mismo origen que aquellas relacionadas
con la autenticidad,[45]
aunque puntualizan en una acción de la performance total: cantar. Siempre en
línea con la concepción documental mencionada, reforzado por el supuesto de que
quien canta tiene las condiciones para hacerlo por sus propios medios y sin
ayuda alguna (entre las cuales se pondera, principalmente, la capacidad de
afinar correctamente los sonidos a cantar), el engaño sería producido por la
introducción de un procesador que afina lo que quien canta no logra hacer por
sus propios medios. Como refieren Díaz-Pinto y Robledo Thompson respecto de la
música popular urbana:
… el uso consuetudinario y opaco - según la conceptualización de Brøvig-Hannsen y Danielsen (2016)
-, que estos músicos hacen en sus producciones fonográficas de tecnologías de
modificación de la voz - como el plugin AutoTune-, han hecho que audiencias más familiarizadas con
los preceptos estético-vocales de otros géneros musicales tiendan a concebir la
incorporación de las mencionadas herramientas de edición no tanto como marcas
estilísticas, sino como testimonio de una falta de habilidad para cantar sin ellas.[46]
En resumen, las controversias planteadas
hasta aquí obligan a formular interrogantes centrales para nuestro trabajo.
Para el trap, ¿Qué significa cantar? ¿Qué
competencias, habilidades y/o cualidades son necesarias para poder hacerlo? Y,
perfilando los interrogantes hacia el centro de interés de nuestro trabajo,
¿hasta qué punto un/a/x cantante puede valerse de recursos tecnológicos para
realizar su performance, sin que esto magulle su autenticidad en cuanto a su
capacidad para cantar?
3.1 Orígenes y características
El trap se originó
a comienzos de los años noventa en los barrios marginales de la ciudad de
Atlanta, Estados Unidos. La música producida bajo esta etiqueta,
particularmente sus letras, buscaba exteriorizar las penurias vividas por los
habitantes de los suburbios de esta ciudad, en gran medida marginalizados[47] Originalmente concebido como un subgénero del
rap, en el trap confluyen también características del
hip hop, el R&B y el freestyle.[48] A
comienzos del siglo XXI, más precisamente entre los años 2000 y 2010, el trap migró desde Estados Unidos hacia España y
Latinoamérica, dando lugar a la emergencia de nuevos artistas y estilos de trap característicos de estos lugares. En el trap latino, son destacables la práctica de la rima
improvisada, las “batallas”, la adhesión explícita a la estética bling-bling, el
uso deliberado de modificaciones de palabras del español, y también la
inclusión en las letras de palabras y/o expresiones tomadas literalmente del
inglés. En cuanto al contenido de las letras, suelen tratarse de historias
vivenciadas por quien las canta, relatadas en primera persona. Las temáticas
pueden ir desde situaciones de marginalidad y exclusión, hasta letras más
superficiales y clichés, historias de éxito, con un objetivo de consumo más
cercano al mainstream.
En este sentido, si bien no forman parte del
centro de interés de este trabajo, es necesario recalcar que el trap, al igual que los estilos englobados dentro de las
etiquetas música urbana y la cultura reggaetón,[49]
no están exentos de críticas. Ellos han sido y continúan siendo objeto de
críticas por sus contenidos, señalados muchas veces como sexistas, misóginos,
violentos y, en ocasiones también, racistas.
En cuanto a sus características musicales, se
conforma por rimas que suelen organizarse en pie ternario. Dado que el énfasis
de la rima está puesto en cómo combinar palabras para producir una expresión
singular, la elaboración melódica de la rima (asociada directamente a la
capacidad que el cantante debería tener para poder realizarla), quedaría, en
principio, en un segundo plano, dando como resultado melodías cuyas
características suelen ser la nota repetida y un movimiento melódico acotado,
que tiene lugar usualmente en un ámbito registral reducido (alcanzando, por
ejemplo, rara vez la octava). La base, o beat,
puede ser un módulo rítmico secuenciado repetitivamente por el tiempo que dure
la rima, o bien ser una pista compuesta para la ocasión que contenga además del
módulo rítmico otros elementos sonoros (una línea melódica de bajo, una
progresión armónica de pocos acordes, entre algunas posibilidades). En derivas
estilísticas en las que el trap se asocia al estilo
canción, estos módulos (usualmente de cuatro u ocho tiempos) pueden recombinarse
para generar las secciones típicas de este estilo (principalmente, estrofas y
estribillos) reiterando y recombinando estos módulos de diferentes maneras. El
tempo característico del trap suele ubicarse en el
rango entre los 130 y 170 PPM.[50]
La persona que encarna el rol de cantante en
el trap suele estar acompañada, en la enorme mayoría
de los casos, por otra que cumple el rol de productor. En efecto, el origen de
la mayoría de las canciones de trap es a partir del
encuentro entre dos personas: cantante y productor o beatmaker.[51]
Mientras el rol del primero estaría delimitado casi exclusivamente a la
creación de las rimas, el productor es el responsable del sonido resultante de
la canción (Johansson, 2020). Habitualmente, el proceso creativo recupera la práctica
improvisatoria del freestyle. La continuación de la
composición es realizada en entornos fonográficos, principalmente digitales. En
efecto, muchos productores cuentan con una computadora portátil que funciona a
modo de meta-instrumento,[52] una
placa de sonido y un micrófono. Con este kit,
que para épocas anteriores hubiera requerido “ … una pequeña empresa al
servicio del músico …”,[53] los
artistas registran, procesan y componen la totalidad de la canción. En línea
con esta práctica, es frecuente que la creación de estas músicas se realice más
a partir de la utilización de una DAW, samples, instrumentos virtuales y procesamientos sonoros in the box,[54] que
a partir del registro de instrumentos mecánico-acústicos, tal como sucede en
otros estilos musicales. Sin embargo, esto no inhabilita la inclusión de tales
instrumentos en el proceso creativo, o en versiones posteriores a la creación
de la canción original.
Cabe destacar que el trap,
es un estilo musical que se caracteriza por estar fuertemente procesado en su
presentación fonográfica. Uno de los procesamientos más destacados en este
sentido es el uso del autotune
en su configuración hard tuning para
el procesamiento de las voces grabadas. Según Ramiro Molina, " … siempre
lo usan. Para estos pibes el autotune es parte
de su estética, es un instrumento más”.[55]
En este estilo, es relativamente habitual
encontrar que tanto cantante como productor no necesariamente tienen una
formación musical previa, en términos de haber realizado y finalizado trayectos
académicos institucionales vinculados con la música. En efecto, el acceso y la
posibilidad de que individuos sin formación musical (académica o no) puedan
crear música se debe en gran medida a la posibilidad que brinda internet para
acceder, de manera legal o a través de la piratería, a los softwares y aplicaciones de producción musical. Como sostiene
Mariano Zukerfeld, además de que el acceso al
hardware necesario para producir música se facilita progresivamente como
consecuencia de la Ley de Moore, “En cualquier caso, parece claro que la
difusión de bienes informacionales relativos a la creación musical, entonces,
permite que el amateur, el músico aficionado, el que solo quiere jugar con la
música, pueda componer”.[56]
El hecho de que el trap
haya surgido y se haya popularizado paralelamente a Internet tiene una doble
incidencia en el estilo y su organización. Simultáneamente, permite hacer uso
de las redes sociales y sus plataformas para poder difundir el material
producido, y establecer redes con quienes escuchan y siguen a sus artistas.
Entrado el siglo XXI, con el advenimiento de la web 2.0 y de las plataformas
UGC[57]
como MySpace o YouTube, entre otras, los artistas y productores musicales ya no
dependen de los canales habituales de la industria discográfica y los medios de
comunicación tradicionales (televisión y radio, como los ejemplos más
salientes) para difundir sus creaciones, sino que pueden hacer uso de estas
para difundir su material, acercarse a sus pares y fidelizar oyentes[58].
Más allá de las modificaciones introducidas
por los desarrollos tecnológicos en relación con las prácticas de producción,
distribución y consumo de la música en el siglo XXI, es pertinente para nuestro
trabajo encuadrar localmente, desde la Argentina, en lo que Guadalupe Gallo y
Pablo Semán nominan como escena musical
“post-Cromañón”.[59] Su
característica sobresaliente es la fragmentación de la escena musical previa al
trágico suceso. De acuerdo con Gallo y Semán, una
escena pre-Cromañón está configurada en apariencia como única, mediada por la
industria discográfica, los medios de comunicación hegemónicos y las prácticas
de comunicación y difusión asociadas a ellos. Luego de la tragedia,[60] los
autores observan la conformación de una nueva configuración, donde ocurre una
dispersión y reagrupamiento atomizado de los actores.
Por último, también es importante considerar
la reunión de etapas de trabajo[61] que
se produce en este estilo, principalmente en torno al productor, en comparación
a otros estilos donde las etapas de producción fonográfica están más claramente
definidas y separadas entre sí.
Desde que el trap argentino nació y logró masificarse, haciéndose
popular a través de la difusión por las redes sociales (principalmente YouTube e Instagram), podemos nombrar a diversos artistas que han alcanzado
un alto grado de popularidad hasta la fecha.
Entre ellos se encuentra
Mauro Lombardo Quiroga (Ciudad de Buenos Aires, 1996), conocido popularmente
como Duki. Lombardo comenzó su incursión en la música
conformando primero agrupaciones que interpretaron más bien música de estilos
relacionados con el rock. En 2010, entró en contacto con la escena del freestyle
porteño, que se configuraría rápidamente como su interés principal. La
atracción que le produjo este estilo lo llevó a participar cada vez más en
“batallas” donde comenzaría a forjar su estilo personal.
En el año 2016 su
popularidad aumentó exponencialmente, en primer lugar, como consecuencia de
haber ganado la edición de El quinto
escalón, certamen dedicado a la promoción y difusión de batallas de rap en
Latinoamérica. En segundo lugar, con la publicación de "She don’t give
a FO", primera canción que alcanzaría el top 100 de Billboard Argentina. El debut discográfico de Duki ocurrió en 2018 con el álbum Super Sangre Joven (SSJ Records - DALE
PLAY Records), lanzado en el mes de agosto de ese
año, con la publicación del sencillo "Goteo". La canción alcanzó el
puesto número 10 en los Billboard charts Argentina hot 100 y en España. En el mismo año, Duki
participó de la ceremonia de los Premios Gardel. A pesar de no haber sido
nominado a ninguna de las categorías, Duki fue
convocado para la el acto de introducción de la ceremonia, en la que cantó su
canción "Rockstar". Como era de esperarse,
utilizó autotune
en su configuración hard tuning. Al
cierre de la ceremonia, Charly García, quien fuera galardonado con el premio
Gardel de Oro por su álbum Random, concluyó su dedicatoria realizada por la premiación
con una lapidaria afirmación, en un claro guiño a la performance inicial de Duki: “ … hay que prohibir el Auto-Tune … gracias”.[62]
El phonographic staging refiere a “una suerte de escenografía
acusmática, en la que efectos tales como reverb, eco, filtrados y sobre grabación actúan como
mediadores de fuentes sonoras grabadas”.[63]
Para nuestro trabajo usaremos la traducción “presentación fonográfica”,
propuesta por Díaz-Pinto y Robledo Thompson. Este concepto nos permitirá
indagar en las operaciones realizadas y los procesadores utilizados en el
diseño de la voz grabada. Esta voz, a su vez, se corresponde con una persona
determinada. En este sentido, utilizaremos las categorías propuestas por Alan
F. Moore, perfomer
(persona real, quien canta) - persona (o persona musical, identidad asumida por
quien canta en el fonograma) - protagonista (persona musical específica,
vinculada a la letra y a la narrativa que conforman la canción). En la misma
línea, realizaremos indagaciones en torno a cuán real o ficticia es la persona,
la situación en la que ella se encuentra (descripta también en términos de real
o ficticia) y, finalmente, la posición del cantante, en tanto persona
involucrada en la lírica de la canción, o como observador de la misma.
En cuanto al concepto de máscara, tomaremos
la definición que propone Philip Tagg, en la que
articula máscara con el concepto de persona:
… el
significado original de la palabra en latín persona es ‘máscara…llevada por
actores en el drama griego y romano’. Los significados transferidos en cuando
al rol performado, personalidad, etc., derivan del
hecho de que revelar la verdadera naturaleza de un personaje dramático
involucraba proyectar la voz de dicho individuo a través de la máscara llevada
por el actor que asumía ese rol. Su voz tenía que, literalmente, sonar (sonare) a través (per) de la máscara - vox personans - hacia el auditorio, hacia el interior de la
audiencia.[64]
Finalmente, usaremos el
concepto de vocalidad, elaborado por Katherine Meizel, definida como “ ‘todo lo que se vocaliza (lo que
suena y se escucha como voz)’, sin que ello refiera únicamente a las palabras
que imparte, al timbre o las técnicas de su producción”.[65] Este
concepto habilita pensar la voz grabada
y procesada como vocalidades, es decir, como
“ensamblajes ecológicos y tecnológicos en tanto formas de vida que desbordan la
condición del humano: el cyborg,
lo monstruoso o el híbrido inter-especies”.[66]
5. Análisis
Para la realización del
análisis haremos una comparación de diferentes aspectos del fonograma original
y del fonograma en vivo de "Goteo". Motiva esta decisión poder
entender y precisar cuáles son las particularidades que guarda este último
respecto del original.
Cabe señalar que el ciclo llamado Paredón sessions
fue concebido con ciertas cualidades y características específicas. De la
hemerografía consultada, recuperamos la siguiente cita que ilustra de manera
sucinta las características principales del ciclo:
Al combinar
cuatro elementos (artista, público, banda en vivo y paredón) el proyecto se
vuelve una experiencia única y muestra cómo las figuras de Trap,
junto a una banda en vivo formada por prestigiosos músicos, salen de su zona de
confort para reversionar sus propios hits y convertirlos en nuevos tracks.[67]
La siguiente imagen (captura del video en vivo),
ilustra la cita anterior:
 Imagen 2:
captura de la presentación en vivo de "Goteo".
Imagen 2:
captura de la presentación en vivo de "Goteo".
Fuente:
https://billboard.com.ar/por-primera-vez-duki-reversiono-goteo-con-bases-en-vivo-mira/
El fonograma en vivo de "Goteo", tomado como objeto de estudio para
nuestro trabajo, guarda cuantiosas similitudes con el fonograma original. La
primera de ellas es la letra cantada. A excepción de la introducción (referida,
en adelante, como intro), en el fonograma en vivo se
conserva la totalidad de la letra original. A continuación, transcribimos los
pasajes que corresponden a cada parte de la canción:[68]
Intro
Yeah, hmm / Ey, ey, ey,
ey, ey / Check /
Verso 1
Quiero un
Felipe Patek / Rolex, Cartier pa'
no ver la hora (Felipe Patek) / Siempre sé lo que hay
que hacer / Duplico otra vez, subo como el dólar (duplico otra ve') / Viven
pendiente 'e mi name / Mi plata, mi ex, shout-out para Lola (sos buena
persona) / No me gustaron sus reglas y fue / Igual toqué los tres día' en el Lolla' (yay, yay)
/
Estribillo
Me puse la'
Gucci con un short de Nike / Buzo y cadena, estoy que goteo (estoy que goteo) /
Sigo volando 'e ciudad en ciudad / Tumbando el club, shout-out
para Neo (estoy que goteo) / Con cara de que nada va a salir mal / Soy un rockstar, 'toy que goteo (estoy
que goteo) / Estoy donde yo le' dije que iba a estar / ¿Ustede'
dónde están? No lo' veo (yay, yay)
/
Verso 2
My life, fast life,
secuencias que van a mil / Falta calma, por eso tomo otra pill
/ No sé cómo dormir, ella se volvió a ir / 6 AM, vuelo pa'
Madrid / Y mientra' fumo le pido a la luna volver a
verte / Yo no sé qué voy a hacer / Solamente siento que me va a atrapar lento
la muerte, mujer /
Verso 3
Toy
que no lo creo / Transpiro oro por los dedo' (transpiro, que) / 'Toy que no lo' veo / El humo me dejó ciego (no veo bien) /
'Toy que no lo creo El Duko
lo hizo de nuevo (no creo que) /'Toy que, ay, goteo
(eh)
Outro (fragmento de Verso 2)
Y mientra' fumo le pido a la luna volver a verte / Yo no sé
qué voy a hacer / Solamente siento que me va a atrapar lento la muerte, mujer
//
Por lo que describe la letra, podemos
entender que se trata de una canción en la que Duki
quiere poner de relieve y mostrar el momento vivido en su historia como
artista, un momento culminante relacionado no solamente con haber alcanzado un
posicionamiento exitoso en el ambiente, sino, principalmente, con el buen pasar
económico logrado y todo lo que éste habilita. En efecto, en la letra
encontramos algunos de los elementos propios de la estética bling bling propios del hip hop, que Arias
Salvado define como una
… forma de vestir heredada del hip hop que, si
bien varía a lo largo de los años, se caracteriza principalmente por el empleo
de cadenas de oro, gafas de sol, gorras o bandanas, ropa deportiva ancha y
zapatillas de deporte, con predilección por las marcas de lujo.[69]
5.2 Música y presentación fonográfica
En la siguiente tabla agrupamos
comparativamente algunos aspectos concernientes a la música y a la presentación
fonográfica que el fonograma en vivo comparte con el fonograma original:
Tabla 1: comparación entre los fonogramas original y
en vivo en Paredón session
de "Goteo".
|
Parámetro
/ Aspecto |
Original |
En
vivo |
|
Tempo |
ca.
150 PPM |
idem |
|
Centro
armónico |
D#m |
idem
|
|
Progresión
armónica |
I bVII bVI ;
bVI bVII I |
idem |
|
Esquema
formal[70] |
Intro
- V1 - E - V2 - E - V3 - V1 - E - V3 - Outro |
idem |
|
Uso
del autotune |
Sí
(¿input/output device?) |
Sí (input y output device) |
Fuente:
elaboración propia.
A
continuación, agrupamos las características singulares de cada fonograma, desde
la perspectiva de análisis de estratos funcionales o functional layers (Moore, 2012):
Tabla 2: comparación entre versiones de
"Goteo", puntualizando los instrumentos y sonidos que ocupan cada uno
de los estratos funcionales o functional layers (Cf. Moore, 2012).
|
Estrato |
Original |
En
vivo |
|
Pulsación
explícita |
Máquina
de ritmo |
Batería
|
|
Bajo
funcional |
Sintetizador
(synth bass) |
Bajo
eléctrico |
|
Melódico |
Primario:
voz principal; secundario: voz coro, melodías teclado |
Primario:
Voz principal; Secundario: voz secundaria (pregrabada), flauta traversa |
|
Armónico |
Sintetizador
simil chiptune[71] |
Teclado;
violín, violonchelo,
flauta traversa |
Fuente: elaboración propia.
Como observamos en la Tabla 2, el fonograma
en vivo está conformado por instrumentos ejecutados, precisamente, por seres
humanos, en vivo y en directo. Al momento de realizar el presente trabajo no
podemos afirmar lo mismo respecto del fonograma original.[72]
La decisión de realizar la presentación en vivo, con una banda integrada por
músicos tocando también en vivo (desmarcándose del formato cantante y beatmaker, habitual
para la escena del freestyle
y las batallas) fue una decisión creativa.[73]
Convocados por Juan Giménez Kuj, director musical a
cargo y bajista del fonograma en vivo, la tarea de los músicos[74]
consistió esencialmente en “llevar al vivo” el fonograma original. Mientras que
la combinación de violín, violonchelo y teclados (con participación ocasional
de la flauta traversa) retoman el estrato armónico del sintetizador símil chiptune, el bajo
eléctrico y la guitarra eléctrica replican en un movimiento paralelo ritmo
armónico y la progresión de acordes. La batería conserva el patrón rítmico
propuesto por la máquina de ritmos en el fonograma original, aunque,
considerando la situación de la performance en vivo, incorpora pasajes y fills ausentes en
el original. Según Ramiro Molina:
el vivo es
la oportunidad también para darle color a la - versión - original. En estos
estilos está bueno meterle onda, que tenga buen groove.
Para eso, muchas veces agregamos fills y cosas que
vienen del R&B, del soul; también del Gospel … hay mucho gospel chops,
fraseo lineal, y esas cosas. Son arreglos que por ahí no están en la versión
original, pero que hacen a la vibe del vivo.[75]
Resulta interesante destacar que la banda
cuenta con una pista que se reproduce en forma sincronizada con su ejecución.
Además de afirmar que esto es una práctica común en este estilo musical, Molina
comenta que
en la pista
tenemos todo. Todos los sonidos, fills y cosas que
tiene la versión original y que nosotros no podemos hacer con nuestros
instrumentos, están ahí. No es playback, pero está bueno sentirse apoyado por
la pista. A veces aparte del clic - metrónomo - hasta tenemos avisos y cuentas
para nosotros grabadas ahí.[76]
En el mismo sentido, amplía:
la pista y
cómo hacés la pista es fundamental para esta música.
No es solamente ponerle los sonidos que no vamos a tocar y listo. Tenés que hacer que esté bueno, que aporte al vibe del vivo. A veces vamos antes de tocar a los lugares
para probar solamente la pista, a ver cómo viene de agudos, cómo están los graves…todo
tiene que estar en su lugar para que la vibe del vivo
sea la mejor.[77]
Como tendencia general, si bien las
características melódicas descriptas anteriormente se conservan (ámbito
reducido y tendencia a la nota repetida), encontramos que en el fonograma en
vivo hay una tendencia del registro en el que Duki
canta más agudo que en el original.
 Imagen 3: transcripciones
de la primera frase de la primera repetición del estribillo de "Goteo" en
versión original y en vivo.
Imagen 3: transcripciones
de la primera frase de la primera repetición del estribillo de "Goteo" en
versión original y en vivo.
Fuente:
elaboración propia.
Esta tendencia alcanza su punto culminante en
la primera repetición del estribillo, donde Duki
realiza un ascenso melódico hasta la altura fa#4, que se configura como clímax
melódico de la canción. Asimismo, la interpreta también como nota repetida, tal
como lo muestra la siguiente transcripción:
 Imagen 4: transcripciones
de la primera frase de la primera repetición del estribillo de "Goteo" en los
fonogramas original y en vivo.
Imagen 4: transcripciones
de la primera frase de la primera repetición del estribillo de "Goteo" en los
fonogramas original y en vivo.
Fuente:
elaboración propia.
A partir de lo expresado anteriormente por
Molina, y como producto de nuestra propia interpretación del fonograma en vivo,
podemos inferir que esta modificación, que lleva prácticamente a llevar a Duki al extremo de su ámbito vocal, puede relacionarse con
la euforia y el bienestar experimentado por el cantante (lo que Molina refiere
como vibe)
al interpretar la canción en vivo y en directo.
En cuanto a la presentación fonográfica de la
voz de Duki en el fonograma en vivo, podemos afirmar
que guarda una relación muy próxima con el fonograma original. En términos de
espacialidad, está ubicada al centro del campo estéreo y en un lugar
protagónico en términos de nivel. Como diferencia entre ambas, podemos señalar
que a la audición comparativa entre versiones, en la original no se oyen
sonidos paraverbales entre frases (por ejemplo, las respiraciones), mientras
que en el fonograma en vivo pueden escucharse con cierta claridad.
En cuanto al uso del autotune, en la audición del fonograma podemos apreciar
el uso de este procesamiento en su configuración hard tuning. Asimismo, durante la entrevista
realizada a Ramiro Molina pudimos recabar que el software utilizado en esta
oportunidad como autotune
"es el Waves Tune, en su modo real time. No es el de Antares ni el Melodyne, que son para estudio, para cosas más finas. Este
es bastante liviano y te permite correrlo como plug-in para usarlo en tiempo real en el vivo".[78] Las
referencias hemerográficas consultadas refuerzan lo mencionado por Molina.
Además, el guitarrista también comenta que es una práctica instalada que, en
este estilo, se cuente con una persona dedicada a la operación del autotune en vivo:
el tunedoctor es
alguien más en la banda que se encarga de manejar el autotune, de tirar efectos (reverbs, delay) en
tiempo real, durante el show. Sabe cuándo tiene que poner el speed en 10, o en
12, para que agarre la nota que tiene que ser. A veces es el sonidista del
vivo, pero sino suele haber alguien de la banda que se encarga de eso.[79]
Tunedoctor[80] es un neologismo que, según
Molina, es común encontrar en la jerga del trap para
referirse a quien está a cargo de la configuración del autotune, entre otros procesos
que se le hacen a la voz en tiempo real, durante el show en vivo. Sin embargo,
cabe destacar que en los créditos publicados del fonograma en vivo no hay
mención al rol Tunedoctor,
ni tampoco a la/s persona/s que estuvieron a cargo de la operación de sonido en
vivo y en directo, lo que oscurece relativamente este rol y cómo fue
configurado el autotune
en tanto input device
para el fonograma en vivo.
El fonograma en vivo de "Goteo" fue
mezclado y masterizado por Mariano Bilinkis. Según él, la propuesta de trabajo para la
postproducción del fonograma fue no distanciarse demasiado de algunos aspectos
del fonograma original, pero destacar las cuestiones propias de la
interpretación en vivo y en directo con instrumentos reales. En este sentido, Bilinkis refiere haber realizado procesamientos a los
instrumentos para que, a la audición, tuvieran mayor “impacto”.[81] A
los fines de este trabajo, resulta revelador que se haya usado autotune
nuevamente en la etapa de postproducción del fonograma, es decir, ahora como output device.
Según Bilinkis, esto se realizó para terminar de
pulir algunas imperfecciones mínimas producto del uso del autotune en su configuración hard tuning como input device,
es decir, durante la interpretación en vivo: “En la mezcla usé un poco de autotune para corregir algunas mínimas cosas que no
vinieron bien del vivo, pero fue mínimo”.[82]
5.3 Conclusión parcial: persona, máscara, vocalidad
A partir de los conceptos de persona (Moore),
máscara (Tagg) y vocalidad
(Meizel) que fueron definidos anteriormente,
encontramos que el fonograma en vivo de "Goteo" guarda una gran
cantidad de similitudes con el fonograma original de la canción. El análisis permitió
confirmar también la puesta en acción de la premisa del ciclo Paredón sessions:
el fonograma en vivo de "Goteo" fue instrumentado con instrumentos
reales, tocado por instrumentistas, articulado con la reproducción de una
pista, todo ejecutado en vivo y en directo. El análisis realizado permitió
indagar sobre la persona musical, el potencial de autenticidad de ella, y su
tensión con los procesamientos realizados a la voz grabada.
En cuanto a la persona musical, encontramos
una coincidencia entre el performer (Mauro Lombardo), la persona musical (Duki) y el personaje que es asumido por ambos en la letra
de la canción. En concomitancia con el tipo de letras propias del freestyle y de
las batallas, la narrativa que despliega la letra en "Goteo" es una
pausa en el vertiginoso ascenso de la carrera artística de Duki,
persona musical encarnada por Mauro Lombardo, la persona real. A partir del
análisis realizado, podemos ver cómo en "Goteo" la distinción
categorial propuesta por Moore se subsume en la persona real que, por tratarse
de una letra absolutamente autorreferencial cantada por el mismo autor,
condensa las otras categorías. En efecto, esto permitiría pensar en una
práctica fonográfica cuya intención fue “capturar y reflejar" lo que
Lombardo canta, lo que, de acuerdo con Moore, aumentaría su potencial
percepción de autenticidad por parte del oyente. Desde la narrativa de la
letra, queda claro que el personaje está poniendo como protagonista de la
historia a la persona (Mauro Lombardo) y un momento particular de su vida como
artista (Duki). En efecto, podemos afirmar que tanto
la persona como la situación propuesta son reales. De la misma manera, el
personaje propuesto en "Goteo", sin distinción entre los fonogramas
original o en vivo, se encuentra completamente involucrado en la narrativa de
la canción.
No obstante, es preciso matizar cómo
tensionan estas distinciones categoriales, particularmente la potencial
percepción de autenticidad de la voz, con las decisiones y procesamientos
sonoros operados en ella desde el entorno fonográfico. Como nos permitió
dilucidar el análisis, la presentación fonográfica del personaje realizada en
el fonograma en vivo de la canción no pretende reflejar necesariamente las
cualidades sónicas de la persona real. Más bien, ella es tomada como punto de
partida para crear una nueva sonoridad resultante: una vocalidad.
De esta manera, la vocalidad de Duki
en el fonograma en vivo es el emergente de la interacción entre la voz grabada
de la persona real, compuesta por la melodía, la letra cantada, y los sonidos
paraverbales producidos por los mecanismos de emisión, y la máscara diseñada en
el entorno fonográfico. La elección de esta expresión (entorno fonográfico) no
es casual. Ella es deudora de la atomización y distribución que han tenido las
tecnologías de producción fonográfica y la consecuente facilidad de acceso que
se ha producido, poniendo en jaque los supuestos que sostienen que determinadas
manipulaciones del sonido deben realizarse en un entorno altamente controlado
(el estudio de grabación, por ejemplo, con condiciones acústicas óptimas) y/o
en una etapa en particular de la producción fonográfica (la postproducción, por
ejemplo). Por otro lado, en la máscara diseñada coinciden tanto las intenciones
artísticas como las correctivas. En este sentido, recordamos el comentario de Bilinkis respecto a los procesamientos utilizados en la
instancia de postproducción del fonograma (uso intensivo de ecualización y
compresión; uso dosificado del autotune), así como también la explicación que brindara
Molina en relación con el uso del autotune durante
el fonograma en vivo. En este, la máscara que se diseña, más precisamente el
uso del autotune en hard tuning, interpela la potencialidad de
percepción de autenticidad, considerando que producir los melismas digitales no
sería posible para Duki si no se articula la
capacidad humana para cantar con el uso del autotune en esta configuración
para producirlos. La vocalidad resultante en el
fonograma en vivo es, entonces, diferente ontológicamente respecto de la voz performada en
vivo, o de la voz grabada previa a la postproducción. No es deudora de una
concepción documental de la fonografía, sino que es producida por una
combinación e integración las agencias maquínicas y
humanas en una única sonoridad.
6. Conclusiones
En el presente trabajo propusimos observar y
describir la utilización del autotune en la canción "Goteo", tomando como
referencia el fonograma en vivo. Esta decisión no fue arbitraria, sino que,
habida cuenta de la frecuente utilización del autotune en el ambiente
controlado del estudio de grabación, entendimos necesario indagar en cómo fue
utilizado este procesador considerando las dos instancias que hacen al
fonograma (performance en vivo y en directo y postproducción de la misma). En
este sentido, el análisis llevado a cabo permitió dilucidar diferentes
cuestiones.
En primer lugar, el trabajo permitió
visibilizar el desplazamiento operado sobre el autotune desde su primera
comercialización en 1997 hasta su utilización en la canción "Goteo",
en 2021. Del secretismo intencionado por Hildebrand al afirmar que “… nadie tiene que saber que una corrección
por software fuera utilizada en las voces grabadas"[83]
a la metáfora de la caja negra referida por Jaime Altozano, solo accesible para
los especialistas en la temática, para pasar al uso deliberado y explícito del
procesador. Lo que comenzó con Cher como factor de diferenciación en la música dance de fines del siglo XX es adoptado,
reutilizado y emplazado como factor de coherencia, como rasgo distintivo de
estilo para el trap. Asimismo, el uso del autotune
analizado en este trabajo permitió visibilizar también cómo este procesador ha
desbordado los confines del estudio de grabación. Aquello previamente reservado
a un espacio determinado, con condiciones acústicas altamente controladas, para
ser operado por usuarios especializados (técnico e ingenieros de sonido)
exclusivamente como output device, se reterritorializa
en el trap en home
studios conformados esencialmente a partir de
entornos fonográficos digitales, y hasta en escenarios para performances en
vivo y en directo donde se utiliza como input
device (recordemos en este sentido la figura del tunedoctor citada anteriormente por Molina).
Consideramos oportuno recuperar la palabra de
Omar Varela, reconocido productor de la escena del trap,
en relación al uso del autotune:
“Capaz la gente flashea que es un loco cantando con Auto-Tune, pero para llegar
a esas melodías, a esos quiebres de voz, estamos horas”.[84]
Contrariamente a esta creencia, encontramos en el fonograma en vivo de
"Goteo" una trama compuesta por diferentes instancias y usuarios del
procesador. En este sentido, podemos afirmar que la participación de diversos
actores en su uso, entendiendo esto como la decisión de su inclusión (a cargo
de quien produjo el fonograma), su configuración (a cargo de quien hizo la
producción, o bien de quien cumplía el rol de tunedoctor) y la operación
interactiva del mismo (quien canta), nos permite afirmar que la agencia sobre
el procesador se encuentra distribuida entre diversos
actores. Ampliando en este sentido, indagamos en el doble uso del autotune, en
tanto input device
durante la performance de la canción en vivo y en directo, y en tanto output device
durante la postproducción del fonograma. Cada uno de ellos respondió a motivaciones
y/o necesidades diferentes. En línea con la afirmación vertida por Frith y Zagorski-Thomas en relación con la interpenetración
dinámica y permanente entre decisiones técnicas, estéticas y musicales,
encontramos que el uso del autotune en su configuración hard tuning durante la performance en vivo es
una práctica habitual en el trap, heredada de la
utilización constante del procesador en el hip hop estadounidense de la primera
década del siglo XXI. Entendemos que este modo de uso y configuración
particular del autotune
produce un nuevo desplazamiento para el procesador: de herramienta de
corrección de afinación a instrumento de creación, determinante para el diseño
de vocalidades singulares. En este sentido, Ramiro
Molina es categórico al respecto:
Si les sacás eso [el autotune] a ellos [cantantes de trap]
es como sacarle la guitarra a un guitarrista. Ellos saben perfectamente cómo
quieren sonar. Las melodías las tienen en la cabeza. El tune les ayuda a estos pibes a poder hacer las melodías que tienen
en la cabeza … No te lo sabrán explicar técnicamente, pero te saben decir si
esta nota no va y hay que cortar o cambiar algo…Para todo eso está el tunedoctor. [85]
Por otro lado, la utilización del autotune en la instancia de postproducción, como
output device,
respondió a una finalidad correctiva, para corregir imperfecciones en la
afinación de pasajes melódicos que, producto de la variabilidad propia de la
interacción cantante-autotune,
puedan haber ocurrido durante la performance
en vivo registrada. En efecto, recuperando las palabras de Ramiro Molina, su vibe, impulsaron
a Duki a interpretar diseños melódicos diferentes al
fonograma original, que en algunos pasajes lo llevaron al límite de sus posibilidades
vocales. En este sentido, podemos afirmar que el autotune operó como una red de
contención, asegurando una performance vocal cuya afinación fuese exacta, con
cierto grado de independencia respecto de la afinación interpretada por Duki.
A modo de corolario, agregaremos algunas
reflexiones respecto del autotune
más allá de la canción aquí analizada. Entendemos que la afirmación que circula
popularmente en torno a, como decía Altozano, “la caja mágica con la que
cualquiera puede cantar” está lejos de ser así. En efecto, sostenemos que una
posición tal, más allá de la crítica que pueda realizarse al autotune en tanto
procesamiento que engaña, no hace más que revelar lo que considero como un
peligroso “alturocentrismo”. En este sentido, se pretendería
reducir la complejidad de una voz cantada y las múltiples vocalidades
posibles a partir de la producción fonográfica a la posible valoración respecto
de la (in)capacidad de quien canta para producir sonidos afinados. Si este
fuera el caso, ¿qué sucede con todas las características y cualidades de la voz
que no se relacionan con la producción de alturas normativizadas dentro del
sistema de temperamento igual? ¿Dónde quedaría entonces, con Barthes, el grano
de la voz?
A partir del trabajo realizado podemos
conjeturar que en estilos musicales como el trap la
capacidad de cantar afinadamente más allá del uso del autotune reviste poco (o tal vez
nulo) interés, desplazando el foco de atención hacia otros aspectos, tales como
la capacidad para valerse del autotune para crear melodías, tener buen flow, la performance en vivo y en
directo, así como también el vestuario, por nombrar solo algunos de los
aspectos ya citados. En efecto, y como mostró el análisis, desde el punto de
vista fonográfico la vocalidad resultante no está
limitada únicamente al uso de autotune. En la sonoridad vocal final intervienen otros
procesamientos tales como, por ejemplo, la ecualización y la comprensión, que
pueden ser tan necesarios como el autotune para lograr el “sonido correcto” desde un punto de
vista estilístico.
Este hecho nos obliga a plantear los
siguientes interrogantes, ¿por qué el uso del autotune en las voces grabadas ha
generado y continúa generando controversias, siendo que, en esta música y en
otros estilos musicales también, la modificación de la afinación de la voz
grabada es sólo uno de los múltiples procesamientos que se le realizan, tanto
con fines correctivos como creativos? En efecto, y puntualizando sobre algunas
otras acciones correctivas que pueden realizarse en la postproducción
fonográfica, ¿por qué no es controversial en la misma medida y alcance que el
uso del autotune,
por ejemplo, el uso de compresores para corregir supuestas imperfecciones en el
rango dinámico, el uso del de-esser[86]
para controlar la sibilancia, o el uso de ecualizadores para modificar
radicalmente el contenido espectral de una voz grabada? ¿Qué sucede entonces
con el overdubbing
para componer frankesteins[87]
en la etapa de edición? En este sentido, pensamos que la persistencia de controversias
de este tipo son deudoras de una concepción que podríamos calificar como
ingenua en relación con los alcances que las prácticas específicas de la
fonografía tienen en la creación musical, particularmente en estilos como el trap. Una ingenuidad tal que, por ignorancia u omisión
deliberada, elude el abordaje de la dimensión fonográfica relegándola a una
cuestión o instancia supuestamente externa a la música. En efecto, consideramos
que muchas de las expresiones que practican la reductio ad absurdum del uso del autotune son
consecuencia de transposiciones apresuradas de características y/o rasgos
normativos de otros estilos musicales en los que el uso del autotune (entre otras tecnologías involucradas en la producción
fonográfica) puede ser connotado negativamente, al entenderse como trampa o
engaño que, supuestamente, enmascara una limitación o imposibilidad
performática. Cabría la posibilidad, entonces, de pensar en engaños lícitos[88] y
engaños ilícitos.
Resulta ilustrativo a los fines de este
artículo recuperar la voz del cantante argentino de trap
Ca7riel, quien se refiere al autotune y al modo
de utilización que Duki hace de éste, destacando la
interacción virtuosa que se produce entre ambos:
El Auto-Tune
otorga, da posibilidades. Si no sabés cantar, hacer
tu primer acercamiento a una base con Auto-Tune te puede cambiar la vida. No se
puede creer. Te da un poder que no tenías, porque cantar es poder. Y a una
persona que tiene ritmo y creatividad, como Duki, le ponés Auto-Tune y ya está, vuela. Duki
es un genio del Auto-Tune, es muy inteligente.
Finalmente, del mismo modo que Simon Frith recuerda en relación con el uso del micrófono
por parte de Frank Sinatra que “tampoco era cuestión para el cantante de
agarrar el micrófono y abrir la boca”,[89]
podemos afirmar que el autotune
no crea cantantes, sino que, en articulación con decisiones artístico-creativas
y correctivas vehiculizadas a partir de procesadores y tecnologías específicas,
participa del diseño de vocalidades singulares.
Arias Salvado, Marina. “Rasgos estilísticos del reggaetón
mainstream, una aproximación desde la producción musical” Etno. Cuadernos de Etnomusicología 15, nro.
2 (2020): 130-165. Disponible en https://bit.ly/3fd1Jyv. Último
acceso: 20/01/2022
Auner, Joseph. “‘Sing
It for Me’: Posthuman Ventriloquism in Recent Popular Music”. Journal of the Royal Musical Association
128, nro. 1 (2003): 98-122.
Basso, Gustavo. Percepción auditiva. Bernal: Universidad Nacional
de Quilmes, 2006.
Besora,
Max y Borja Bagunyà. Trapologia. Barcelona: Ara
libres, 2018.
Brøvig-Hanssen,
Ragnhild y Anne Danielsen. Digital
signatures. The impact of digitization on popular music sound. Cambridge y Londres: MIT Press, 2016.
Clendenning, Jane. “Electronically Modified
Voices as Expressing the (Post)Human condition in Daft Punk’s Random Access Memories (2013)”, en The Routledge
companion to popular music analysis, ed. Ciro Scotto, Kenneth Smith y John Backett. Londres: Routledge, 2019.
Díaz-Pinto, Ana María Macarena Robledo-Thompson. “‘Voy
conociendo mi voz, me voy encontrando en mi flow’:
performance vocal y musical en el reggaetón y trap
latino a través del caso de Bryant Myers”. Contrapulso: revista latinoamericana de estudios en música popular 3, nro. 2, (2021): 39-56. Disponible en: https://doi.org/10.53689/cp.v3i2,123. Último
acceso: 25/01/2022.
Doallo, Darío. “Omar
Varela, el productor estrella del trap local, antes
del Lollapalooza 2019: “Siempre hago locuras con la
música”. Clarín, Buenos Aires (26 de marzo de 2019). Disponible en: https://www.clarin.com/espectaculos/musica/omar-varela-productor-estrella-trap-local-lollapalooza-2019-siempre-hago-locuras-musica_0_TlfTyQwu1.html? . Último
acceso: 26/01/2022.
Eckard, Greg.
"Cómo un ingeniero petroquímico creó auto-tune y
cambió la música para siempre. Una entrevista con el revolucionario inventor
Andy Hildebrand", 2016. Disponible en https://www.vice.com/es/article/bmaj4d/soundcollective-como-un-ingeniero-petroquimico-creo-auto-tune-y-cambio-la-musica-para-siempre Último acceso: 04/01/2022.
Fernández, José Luis. Postbroadcasting. Innovación en la industria musical.
Buenos Aires: La crujía, 2014.
Frith, Simon. Ritos de la interpretación: sobre el valor
de la música popular. Buenos Aires: Paidós,
2014.
Frith, Simon y Simon Zagorski-Thomas.
The Art of Record Production. An
Introductory Reader for a New Academic Field. Farnham: Ashgate, 2012.
Gallo, Guadalupe y Pablo Semán. Gestionar, mezclar, habitar. Claves en los emprendimientos
musicales contemporáneos. Buenos
Aires: Editorial Gorla, 2016.
Johansson, Ola. Songs from Sweden. Shaping Pop Culture in a Globalized Music
Industry. Singapur: Palgrave Pivot, 2020.
Katz, Mark. Capturing
sound: how technology has changed music. Los Angeles: University of
California Press, 2010.
Kelly, Caleb. Cracked media: the sound of malfunction. Cambridge: MIT Press,
2009.
Lacasse, Serge. “Persona, emotions and
technology: The phonographic staging of the popular music voice”, CHARM
symposium 2: The art of record
production, 2005. Disponible en :
https://charm.cch.kcl.ac.uk/redist/pdf/s2Lacasse.pdf. Último
acceso: 06/02/2022
Lahiteau, Luciano. Los desafinados también tienen corazón: una
historia del Auto-Tune. Ciudad de La Plata: Firpo Casa Editora, 2021.
Moore, Allan F. Song means: analysing
and interpreting recorded
popular songs. London: Ashgate
publishing, 2012.
Moorefield, Virgil. The producer
as composer. Shaping the Sounds of Popular Music. Massachusetts: MIT Press,
2010.
Milner, Greg. Perfecting sound forever: an aural history of recorded music. Londres: Granta Books, 2010.
Noor, Lobad.
“Auto-Tune In Hip-Hop: A Brief History From T-Pain To Future” en HNHH (Hot New Hip-Hop), 2020. Disponible en: https://www.hotnewhiphop.com/auto-tune-in-hip-hop-a-brief-history-from-t-pain-to-future-news.122367.html. Último acceso: 06/01/2022
Osorio Fernández, Javier.
“Conexiones posthumanas: animalidad, tecnología y
otras vocalidades”. Resonancias, vol. 25,
nro.49, (2021): 171-175. Disponible en: http://resonancias.uc.cl/es/N%C2%BA-49/conexiones-posthumanas-animalidad-tecnologia-y-otras-vocalidades.html#_ftn4. Último acceso: 05/01/2022
Tagg,
Philip. Music's meanings: a modern
musicology for non-musos.
Huddersfield: The Mass Media Music Scholars Press Inc, 2013.
Sterne, Jonathan. The Audible
Past: Cultural Origins of Sound Reproduction. Durham, NC: Duke University Press, 2003.
——— . MP3: the meaning of a format.
Durham, NC: Duke University Press, 2012.
Van Dijck, José. La cultura de la conectividad: una historia
crítica de las redes sociales. Buenos Aires: Siglo XXI editores, 2016.
Zagorski-Thomas, Simon. The Musicology of Record Production. Cambridge: Cambridge
University Press, 2014.
Zukerfeld, Mariano. Obreros de los bits: conocimiento, trabajo y tecnologías digitales.
Bernal: Universidad Nacional de Quilmes Editorial, 2013.
Discografía
Duki: “Goteo” en Super
Sangre Joven, Buenos Aires, SSJ Records - DALE
PLAY Records, 2018. Disponible en: https://open.spotify.com/track/1EoEU4HY57qaITp06TkC6B?si=8afb12bb64364455
Duki (2019): “Goteo” en Paredon live session,
Buenos Aires, SSJ Records - DALE PLAY Records. Disponible en: https://open.spotify.com/track/5ZCZJDUmLeIYwv8yPZUge9?si=92fd299077804b31
Referencias multimediales
Altozano, Jaime. (2019) “La INCREÍBLE Historia del
AUTOTUNE”. Disponible en https://www.youtube.com/watch?v=a_H1nQkGUrE. Último
acceso: 03/01/2022
——— (2019), “La Verdad sobre la Música POP”.
Disponible en https://www.youtube.com/watch?v=ySa67e0jKNA. Último acceso:
03/01/2022